2021 iThome 鐵人賽
分享至
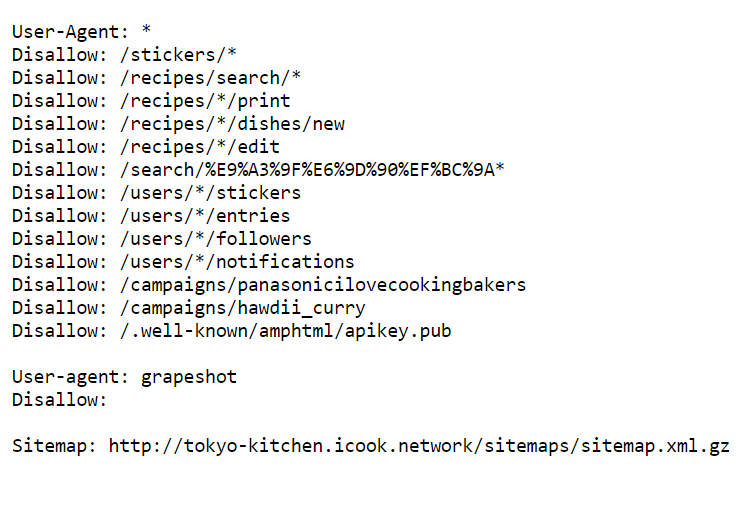
這邊想說一下,關於上一篇有講到我利用superagent()來獲得網站資訊,結果抓取失敗。這是因為不一定所有網站都願意其他人隨便沿用自己的東西,所以在網站後台可以讓人設定禁止令之類的,防止他人搜索。那要如何知道網站是否同意進行搜索,可以在網址根目錄後加上robots.txt就會看到文字檔紀錄,像是用戶代理、禁止目錄…等等。下面是我上一篇失敗網站的文字檔。總而言之,就是禁止了很多東西,導致我抓取失敗了!之後我稍微補充下robots.txt的基本應用吧。
常見用詞:
常見應用:
IT邦幫忙